
Por Mario Ishikawa e Alexandre Patrus
Muitos agentes da transformação digital ainda não conheceram o que é o Unified Namespace. Também abreviado como UNS, esse termo foi cunhado por Walker Reynolds, presidente da 4.0 Solutions, para designar um conceito que permite o processamento e o tráfego, em tempo real, de informações contextualizadas, normalizadas e agregadas. Portanto, o UNS não é um produto e nem um sistema, mas uma ferramenta fundamental para o cenário da Indústria 4.0. E neste artigo vamos te explicar o por quê.
É muito comum as pessoas pensarem que não existe um problema de coleta e processamento de dados em suas empresas, pois o cenário da Indústria 3.0 e da automação das fábricas já trabalha com coleta de dados. Porém, quando falamos em Indústria 4.0, estamos falando de uma quantidade muito maior de equipamentos conectados na rede de uma planta. E o UNS vem para ajudar a permitir a escalabilidade da sua estratégia de transformação digital.
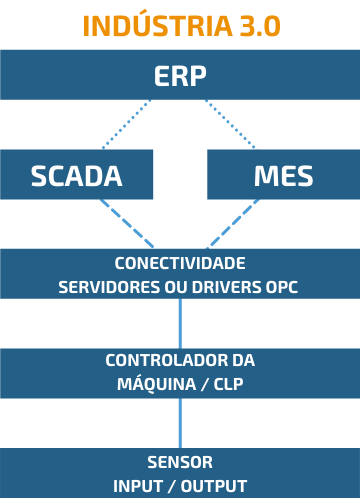
Indústria 3.0 x Indústria 4.0: quais as principais diferenças no fluxo de dados?
Neste exemplo, podemos ver um cenário típico da Indústria 3.0: os dados fluem em apenas um sentido. Eles vão dos sensores para os CLPs, dos CLPs para os sistemas SCADA ou MES, e em algumas vezes também vão para o ERP.
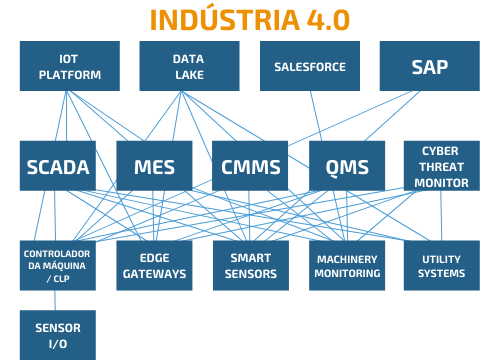
Mas na Indústria 4.0 nós temos uma situação diferente. Os nós no ecossistema não são apenas geradores ou consumidores. Devemos considerar que qualquer nó na rede pode ser tanto gerador quanto consumidor. Por exemplo, um sistema de controle avançado em que o CLP recebe informações de machine learning para devolver resultados. Ou também um sistema MES que envie dados de volta para o sistema SCADA ou um sistema de ERP.
Como o UNS é aplicado?
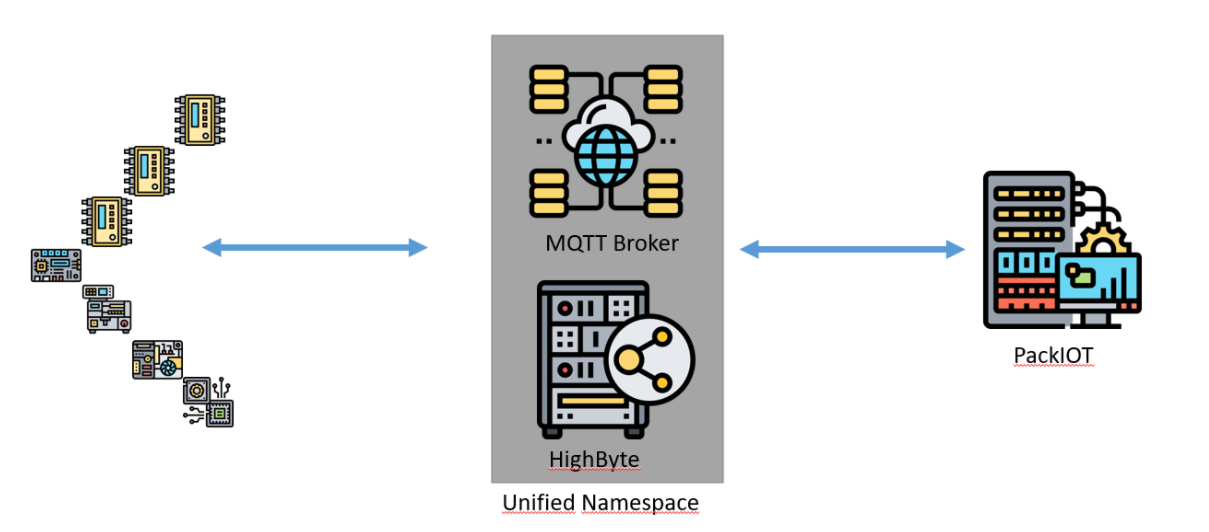
Na imagem acima você pode ver uma aplicação do UNS. O MQTT Broker permite a comunicação entre os diversos nós do ecossistema (que agora serão geradores e consumidores de dados, lembra? Por isso a seta possui dois sentidos). E enquanto o MQTT permite essa comunicação, o HighByte contextualiza esses dados e os devolve para o MQTT Broker. Esses dados podem ir para a nuvem e podem ser visualizados em uma ferramenta de BI e em uma ferramenta SCADA. Estamos falando de dados contextualizados oriundos de CLPs, ERPs, MES, do Sistema de Qualidade, Sistemas de Manutenção, software de planejamento e controle de produção, entre outros.
Como fica a arquitetura do projeto?
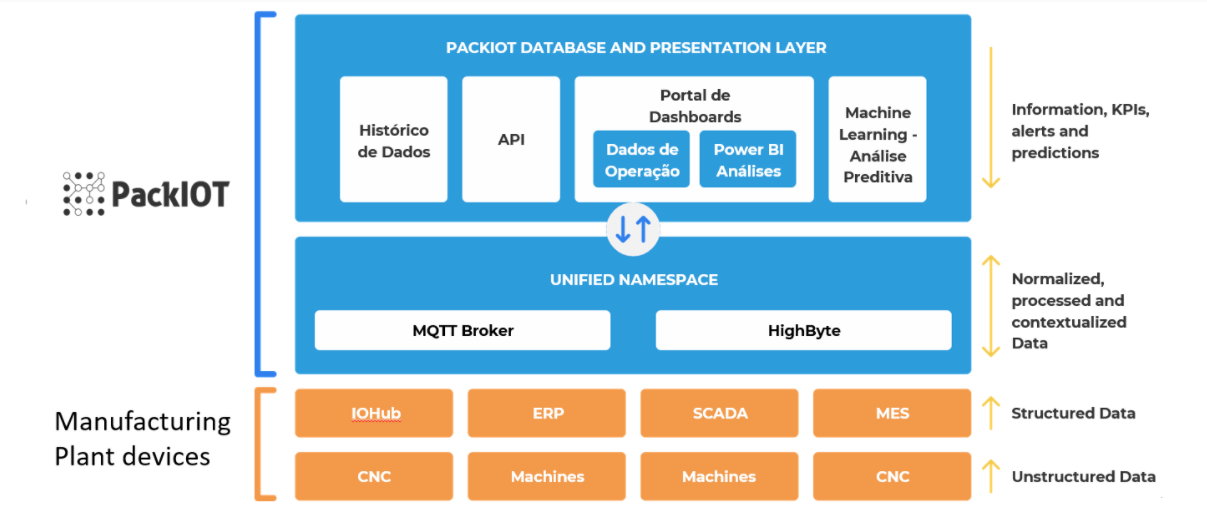
Na imagem acima, você tem um resumo da arquitetura do projeto. A parte laranja simboliza o que a fábrica já possui. Máquinas e CNCs com dados não estruturados. São CLPs funcionando como registradores que enviam dados para um Data Lake e nesse contexto nenhuma informação será obtida.
Ao passar por uma segunda camada, por exemplo um gateway, um ERP, SCADA ou MES, estamos falando de dados estruturados. Esses dados já fazem algum sentido, mas ainda não fazem muito sentido se visualizados isoladamente.
O Unified Namespace vem para coletar todos esses dados e adicionar contexto a eles. Contextualização significa juntar dados de diversas fontes diferentes para um mesmo elemento. Na imagem abaixo temos uma tela de um OPC Browser que mostra dois CLPs com informações relevantes sobre um mesmo equipamento.
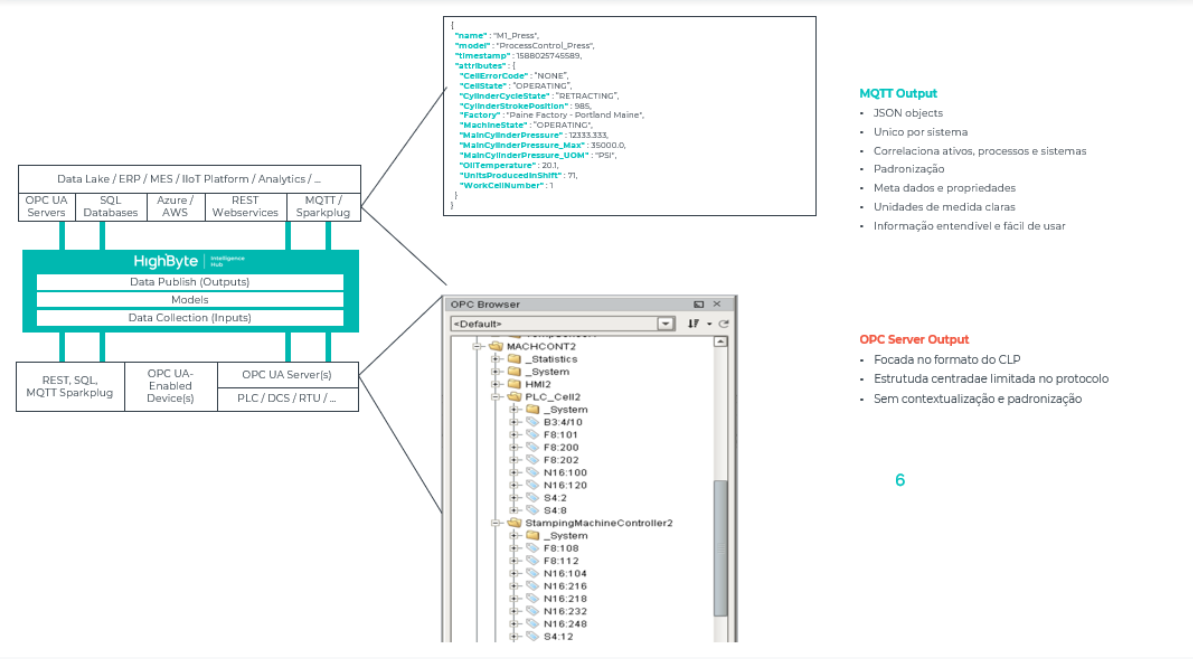
Se temos uma informação vindo de um OPCUA, significa que temos meros registradores que trazem valores em tempo real de dois CLPs diferentes e esse tipo de ferramenta, sem contexto, não auxilia uma cientista de dados, uma tomadora de decisão ou uma gerente de manutenção. Elas precisam de mais contexto.
Não importa que o dado da “Máquina A” venha de dois CLPs diferentes, eles devem vir normalizados, contextualizados e em um só lugar. Uma ferramenta de DataOPS vem para juntar esses diferentes namespaces, de um CLP A e um CLP B e os coloca dentro de um objeto que identifica sobre qual máquina estamos falando.
O ideal, nesse caso, é usar o ISA-95, que divide um empreendimento entre site, área e linhas para fazermos com que todos os elementos dessa hierarquia forneçam informações estruturadas em um formato JSON.
E esse é um dos grandes benefícios de uma ferramenta de Data OPS como o HighByte, pois ele nos permite trabalhar com essa modelagem. Imagine que uma mesma máquina forneça dados para sistemas diferentes. Para um ERP, ela é chamada de Máquina A. Em um MES, ela é conhecida como Machine A e em um CLP ela é nomeada de M1. O HighByte irá criar um modelo dessa máquina e definirá a estrutura de propriedades e criará instâncias dessa máquina. Não importa se cada propriedade vem de fontes diferentes, agora haverá contexto e organização para sabermos que estamos falando sempre da mesma máquina.
Outro erro comum é achar que você pode pegar dados do seu CLP e enviar direto para um Data Lake na nuvem e usar isso para aplicar conceitos de machine learning posteriormente. O erro, nesse caso, se encontra na falta de contextualização. Se você envia para um Data Lake uma informação como “Byte 0, Valor 50”, você não saberá se esse valor de 50 é uma temperatura, ou uma contagem de peças, e isso não ajudará em nada um algoritmo de machine learning.
E quais são os pré-requisitos para ter um sistema como esse?
De acordo com Walker Reynolds, são necessários quatro principais requisitos para a implantação de um sistema como o UNS: o foco deve estar no Edge, reportar por exceção, transmissão leve e arquitetura aberta. Explicaremos cada um deles a seguir.
1_Foco no Edge
Os dados devem ser processados o mais proximamente possível das máquinas. E esse processamento deverá ocorrer de maneira adequada com normalização dos dados e através de agregações simples.
2_Reportar por exceção
Os dados serão transmitidos apenas quando a mudança for relevante. É sabido que, a cada segundo, menos de 10% dos dados sofrem mudanças de fato. E serão nesses momentos que eles serão transmitidos, porque quando falamos de centenas ou milhares de nós distribuídos na rede e sendo requisitados, o projeto se torna inviável caso haja transmissão de todos os dados continuamente. Deve-se transmitir um dado apenas mediante uma variação.
3_Transmissão leve
É necessário um protocolo de transmissão de dados tal como o MQTT, que é um protocolo leve nos momentos de transmissão de rede, de comunicação e de conexão. Tal protocolo também suporta a rotina de reportar por exceção, fazendo com que seja o ideal para esse tipo de rede.
4_Arquitetura aberta
Sob a ótica da Indústria 4.0, não podemos pensar em transformação digital através de soluções fechadas ou com soluções de um mesmo fabricante. Temos que trabalhar com arquitetura aberta para pensarmos em escalabilidade. Não podemos começar um projeto inicial com iniciativas que comprometam projetos futuros e expansões. É fundamental que os elementos de toda a camada de tecnologia consigam se comunicar.
Então, qual é o benefício de um Unified Namespace?
A partir do momento em que você implementa um sistema como o UNS, você terá dados de diversas fontes distintas estruturados, organizados e contextualizados. Saberá precisar que a “Máquina A” produziu Y peças, em uma temperatura Z, no turno T. Durante a produção das peças, que foram enviadas para o cliente C no dia D, houve N paradas não programadas e o OEE foi de X. Imagine o número de dados que foram processados para que todo esse contexto tenha sido criado.
Ou seja, um UNS minimiza o número de conexões de 1 para 1 e um emaranhado de transmissão de dados. No sistema de telefonia, por exemplo, os telefones não são vendidos aos pares. Existe uma central telefônica que permite que pessoas possam ligar umas para as outras, de diversos números diferentes, que passam por essa central. A mesma coisa acontece na Indústria 4.0 quando pensamos no Unified Namespace. Como as informações passarão por essa central, o UNS, você evitará um ‘espaguete de dados’ ou uma bagunça no tráfego de informações, algo fundamental quando pensa-se que o sistema de uma planta industrial possui milhares de agentes.


