
By Mario Ishikawa and Alexandre Patrus
Many digital transformation actors are not yet familiar with Unified Namespace. Also abbreviated as UNS, this term was coined by Walker Reynolds, president of 4.0 Solutions, to designate a concept that allows real-time processing and traffic of contextualized, normalized, and aggregated information. Therefore, the UNS is neither a product nor a system, but a central tool for the Industry 4.0 scenario. And in this article we will explain why.
It is very common for people to think that there is no data collection and processing problem in their companies, because the Industry 3.0 and factory automation scenario already works with data collection. However, when we talk abou Industry 4.0, we are talking about a much larger amount of equipment connected to a plant’s network. And the UNS comes to help enabling the scalability of your digital transformation strategy.
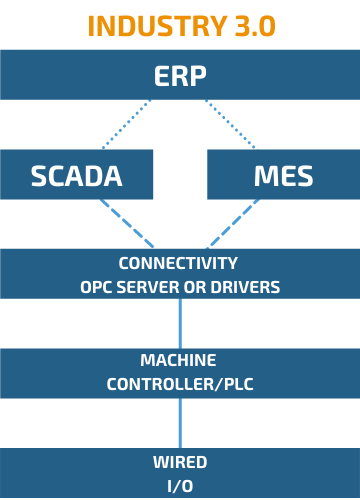
Industry 3.0 x Industry 4.0: what are the main differences in data flow?
In this example, we can see a typical Industry 3.0 scenario: data flows in one direction only. It goes from the sensors to the PLCs, from the PLCs to the SCADA or MES systems, and sometimes also to the ERP.
But in Industry 4.0, we have a different situation. The nodes in the ecosystem are not just generators or consumers, exclusively. We should consider that any node in the network can be both generator and consumer. For example, an advanced control system in which the PLC receives information from machine learning as a setpoint suggestion. Or also a MES system that send data back to the SCADA system or an ERP system.
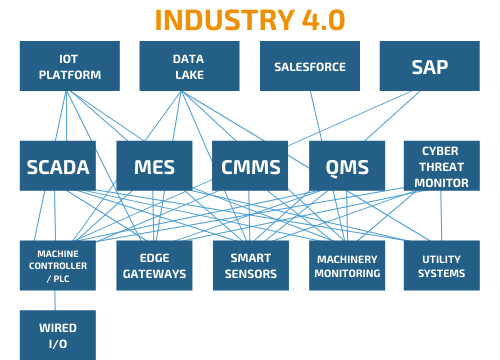
How is the UNS applied?
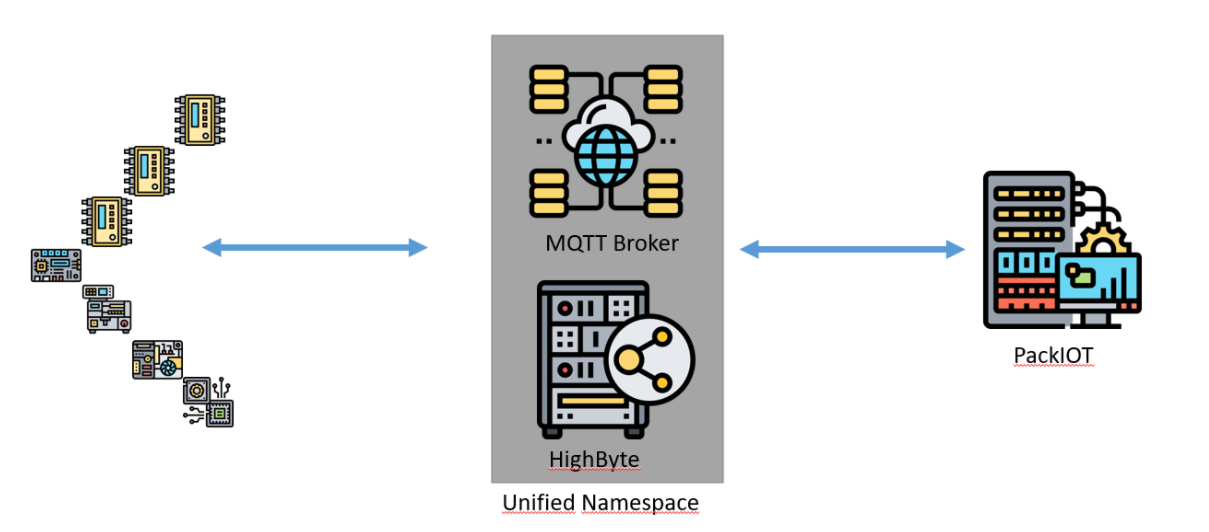
In the image above, you can see an application of the UNS. The MQTT Broker allows the communication between the various nodes of the ecosystem (which will now be data generators and data consumers, remember? That’s why the arrow has two directions.) And while MQTT enables this communication, HighByte, an Industrial DataOps tool, contextualizes this data and feeds it back to the MQTT Broker. This data can go to the cloud and can be visualized in a BI tool and in a SCADA tool. We are talking about contextualized data coming from PLCs, ERPs, MES, Quality Systems, Maintenance Systems, production planning and control software, among others.
What does the architecture of the project look like?
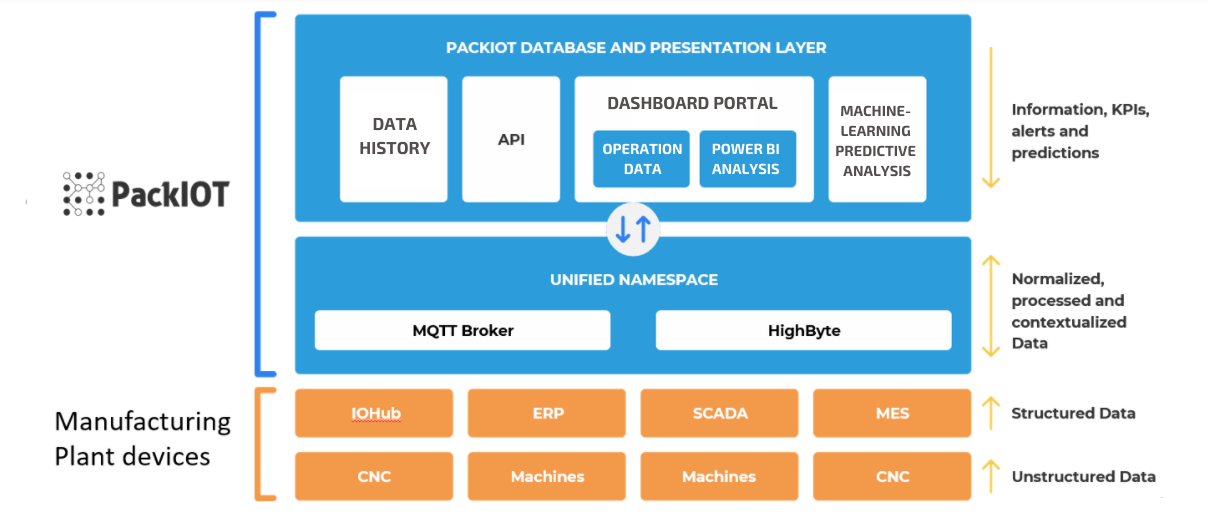
In the image above, you have a summary of the architecture of the project. The orange part symbolizes what the factory already has. Machines and CNCs with unstructured data. These are PLCs working with registers and bytes that if sent to a Data Lake with no context, no information will be retrieved.
When passing through a second layer, for example a gateway, an ERP, SCADA, or MES, we are talking about structured data. This data already makes some sense, but it still doesn’t make much sense if viewed as it is.
The Unified Namespace comes to collect all this data and to add context to it. Contextualization means bringing together data from many different sources into a single element and timestamp. In the image below we have a screen from an OPC Browser that shows two PLCs with relevant information about the same equipment.
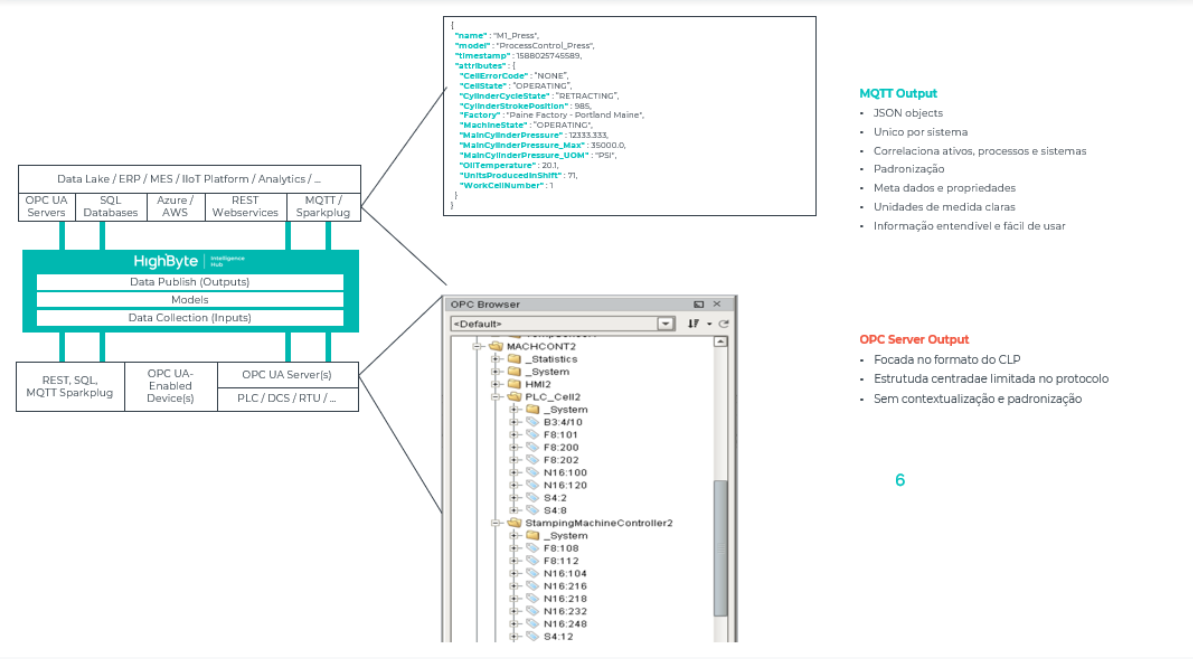
If we have information coming from an OPC-UA server, it means that we have mere registers bringing real-time values from different PLCs and this kind of tool, without content, does not help a data scientist, a decision maker or a maintenance manager. They need more context.
It doesn’t matter that the data from “Machine A” comes from two different PLCs, it must come normalized, contextualized, and in one place. A DataOPS tool comes in to put these different namespaces, from PLC A and PLC B, together and place them into an object that identifies which machine we are talking about.
The ideal scenario here is to use ISA-95, which categorizes an enterprise between site, area, and lines to make all the elements of this hierarchy topresent structured infromation in a JSON format.
And this is one of the great benefits of a DataOPS tool like HighByte, because it allows us to work with this modeling. Imagine that the same machine provides data for different systems. For an ERP, it is called MachA. In an MES, it is known as Machine A, and in a PLC, it is called M1. HighByte will create a model of this machine and define the structure of properties, allowing instances of this machine model to be created. It doesn’t matter if each property comes from different sources. Now there will be context and organization so we know we are always talking about the same machine.
CASE at Granado: How PackIOT helped a modern industry with real-time data collection
Another common mistake is to think that you can take data from your PLC and send it straight to a Data Lake in the cloud and use that to apply machine learning algorithms later. The mistake, in this case, lies in the lack of contextualization. If you send to a Data Lake information like “Byte 0, Value 50”, you won’t know if this value of 50 is a temperature, or a partial count, and this will not help a machine learning algorithm at all.
And what are the prerequisites for having such a system?
According to Walker Reynolds, there are four main requirements for implementing a system like UNS: Edge focused, report by exception, lightweight streaming, and open architecture. We will explain each of these below.
1_ Edge Focused
Data should be processed as close to machines as possible. And this processing should occur in a proper way, with data normalization and simple aggregations.
2_ Report by exception
Data will be transmitted only when the change is relevant. It is known that every second less than 10% of the data actually changes. When we talk about hundreds of thousands of nodes distributed in the network and being requested, the project becomes unfeasible to transmit all the data continuously. A data should be transmitted only upon change.
3_ Lightweight
A data transmission protocol such as MQTT is needed, due to its lightweight nature. Such protocol also supports the report-by-exception routine, making it ideal for this type of network.
4_ Open Architecture
From an Industry 4.0 perspective, we cannot think of digital transformation through closed solutions or with solutions from a single manufacturer. We have to work with open architecture to think about scalability. We cannot start an initial project with initiatives that compromise future pojects and expansions. It is fundamental that the elements of the entire technology layer are able to communicate.
So, what is the benefit of a Unified Namespace?
From the moment you implement a system like UNS, you will have data from many different sources structured, organized and contextualized. You will know that “Machine A” produced Y parts, at T temperature, on shift S. During the production of the parts, which where shipped to customer C on day D, there were N unscheduled stops and the OEE was X. Imagine the amount of data that had to be processed for all this context to be created.
In other words, a UNS eliminates point to point connections and minimizes the load on data transmission. In the telephone system, for example, telephones are not sold in pairs. There is a telephone station that allows people to call each other from many different numbers that go through that station. The same thing happens in Industry 4.0 when we think about Unified Namespace. As the information will go through this central, the UNS, you will avoid a ‘data spaghetti’ or a mess of information traffic, something fundamental when you think that the system of an industrial plant has thousands of agents.


